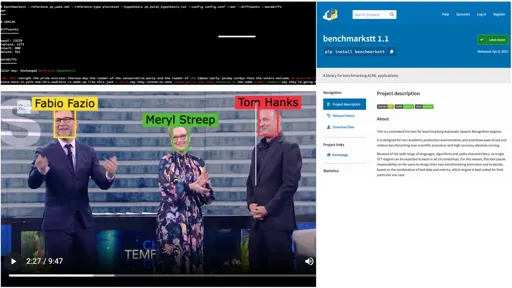
This project group started with BenchmarkSTT, a tool to facilitate benchmarking of speech-to-text systems and services. Now, the working group is developing an open-source pipeline for facial recognition in videos. For comparative evaluation, the team has developed one of the largest datasets for Machine Learning of annotated videos with about 700 celebrities over 78 hours of TV content.
We are now working on experimenting with LLM and generative AI for media apllications
2024
 Evaluation of and experimentation with LLM/RAG/Agent for Q&A on owned content
Evaluation of and experimentation with LLM/RAG/Agent for Q&A on owned content
2023
 Development of an open-source facial recognition system for video
Development of an open-source facial recognition system for video- Development of metrics to evaluate facial recognition systems for video
- Organise a workshop on Facial Recognition evaluation strategy for broadcasters
- Develop an annotated dataset to evaluate face recognition systems on tv programmes
2022
- Development of a facial recognition system for images
- Definition of metrics to evaluate facial recognition systems for video
- Development of a semi-automatic annotation pipeline on AWS
- Start the writing of a report on best practices and state of the art on facial recognition
2021
- Publish BenchmarkSTT tool 1.1
- Start the development of a facial recognition system for video
2020
- Add the Levenshtein distance to the STT benchmarking code
- Test the STT benchmarking API and Docker image
- Publish STT benchmarking release 1.0.0 on PyPi
- Update the STT benchmarking documentation on ReadTheDocs
- Organise a Webinar
- Develop the STT benchmarking new metrics for 1.1 on Github
BenchmarkSTT
Unlike tools used by ML experts in academic settings, BenchmarkSTT targets non-specialists in production environments. It does not require meticulous preparation of test data, and it prioritises simplicity, automation and relative ranking over scientific precision and absolute scores.
With a single command, the tool calculates the accuracy of Automatic Speech Recognition (ASR) transcripts against a reference. Optionally, the user can apply normalization rules to remove non-significant differences such as case or punctuation. Supporting multiple languages and user-defined normalizations, this CLI tool can be integrated into production workflows to perform real-time benchmarking.
Open Source
This collaborative project is open source.
- BenchmarkSTT is available on GitHub: github.com/ebu/benchmarkstt
- The first release has been published on PyPi: pypi.org/project/benchmarkstt/
- It is fully documented on ReadTheDocs: benchmarkstt.readthedocs.io/en/latest/
Webinar
Contributors and users of the opensource 'STT Benchmarking' explain the tool's principles, useful metrics and applications.
The second part of the webinar addresses developers and provides an overview of the code and guidance for its integration.